For this post I decided I would outline the steps that I took in creating a relatively simple relational database using SQL Server. I got the idea when a buddy and I decided we wanted to document our gym progress for next couple of months. I wanted to challenge myself a bit and decided to create a database that can be adapted for multiple users.
I used a “waterfall” development model where the creation of the database follows a linear sequence. The design of this database followed the steps outlined in the database life cycle (DBLC). It contains 6 phases which are: database initial study, database design, implementation and loading, testing and evaluation, operation/ maintenance and evolution. For length purposes of this post, I will walk you all the way through the implementation and loading phase of the DBLC.
Initial Study/Database Design
The steps I took for the study and conceptual design are as follows:
- Data Analysis and Requirements,
- Entity Relationship modeling and normalization,
- Data Model verification
- Distributed database design.
More specifically, I first gathered the requirements by asking questions and established the business rules:


A good design starts with identifying entities and attributes and the relationships between the entities. From the above business rules I was able to establish entity names. This was easy because they are usually the nouns.
I then was able to create an attribute list (column names) for all the entities and establish the relationships between the entities. Relationships can be described as one to many, one to one or many to many. Usually when two entities have a many to many relationship, a junction table is needed with a composite key (two primary keys together) to mediate this. That is why you will see many junction tables below. Note that the primary keys are underlined.

Next I confirmed that the model shown above is in third normal form (3NF). Normalization is a technique used to design tables in which redundancies are minimized. For this database I stopped at 3NF which is most common for databases. While conducting normalization checks, new entities were formed. Please read below for more details on normalization:
- First normal form (1NF) is the first stage of the normalization process. It describes a relation with no repeating groups and a primary key that is identified. All non key attributes in the relation are dependent on the primary key.
- Second normal form (2NF) is is when the relation is in 1NF and there are no partial dependencies. Normally if a relation has one primary key then it is most likely in 2nd normal form.
- Third normal form (3NF) is the stage in which it is in 2NF and no non key attribute is functionally dependent on another non key attribute.
With all the above completed, below is the Entity Relationship Diagram (ERD) I was able to come up with. The ERD created shows connectivity, cardinality notations, relationship strengths and follows Crow’s Foot Notation :

For this database model I chose not to identify any fan traps (when you have one entity with two one to many relationships). The main concern with this would be data redundancy. However, sometimes it is okay if it can help functionality and follows your business rules.
Implementation and Loading
After we verify the ERD created above we move on to the implementation phase. In the implementation phase, the conceptual design is translated into a physical design which is accompanied by a data dictionary. The data dictionary is a logical representation (logical schema) of the relational database system. While some programs can create the data dictionary for you, I was inclined to create one myself for the practice.
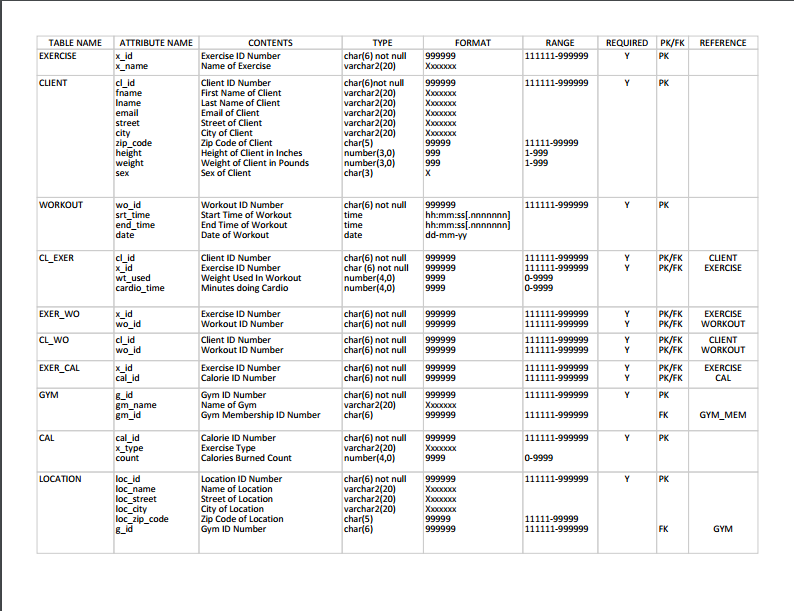
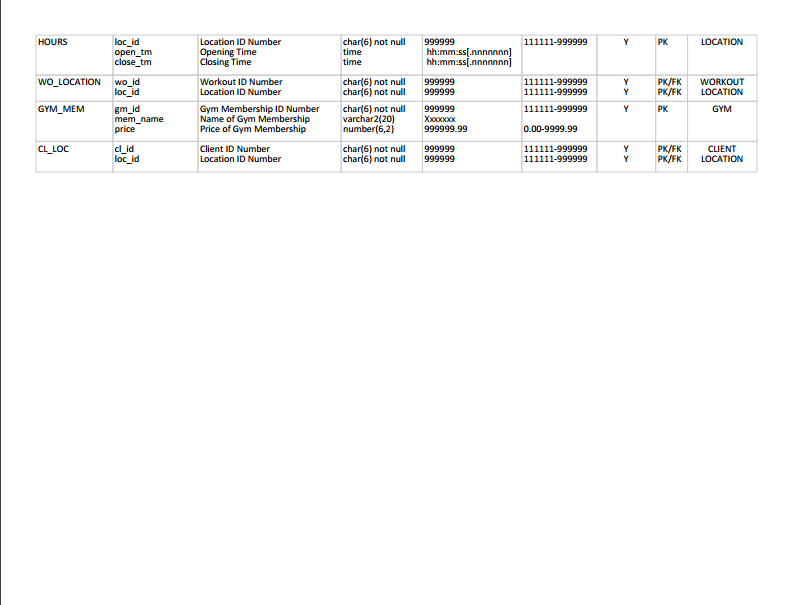
We are then all cleared to physically create tables using SQL statements. The SQL code can be found below. The SQL code gives the RDBMS instructions to create the tables and establish the relationships between entities. All this information (primary keys, constraints, integrity rules) can be found and converted from the data dictionary above. After this step, the database can be populated by using more SQL statements. We can then proceed to testing and evaluation by querying the database.